目前的大型語言模型(LLMs)雖然在多任務處理上表現優異,但其主要依賴於基於單字或子詞的逐步生成,與人類多層次抽象推理能力存在差距。
傳統LLMs的局限性
缺乏多層次推理能力:傳統LLMs(如GPT、Claude)在文本生成時逐字預測,雖然效果流暢,但缺乏明確的層次化規劃能力。
語言中心化問題:多數LLMs以英語為中心,對低資源語言的支援較弱。
長文本產生一致性問題:在產生長文本時,傳統LLMs難以保持邏輯一致性。
人類在處理複雜任務時,通常從高層次概念規劃入手,再逐步細化,而現有LLMs缺乏顯性的層次化結構。
Meta AI提出了一種新的大語言模型架構“Large Concept Model (LCM)”,旨在以更高層次的語義表示(概念 concept)進行推理和生成,跨越語言和模態的限制。
與傳統語言模型(如GPT)逐字生成不同,LCM的核心概念是基於「概念」(concept)進行語言處理,把每個句子看作一個「概念」concept),在句子層次進行推理和生成,而不是傳統模型的“詞元”(token)級別操作。它的目標是讓模型更像人類思考,先從大框架著手,再填充細節。
具體來說:
概念(Concept):在LCM中,一個概念通常對應一個完整的句子,它是語言和模態無關的高階語義表示。
設計目標:從更高的抽象層次進行推理和生成,超越現有模型限制,處理更複雜的任務。
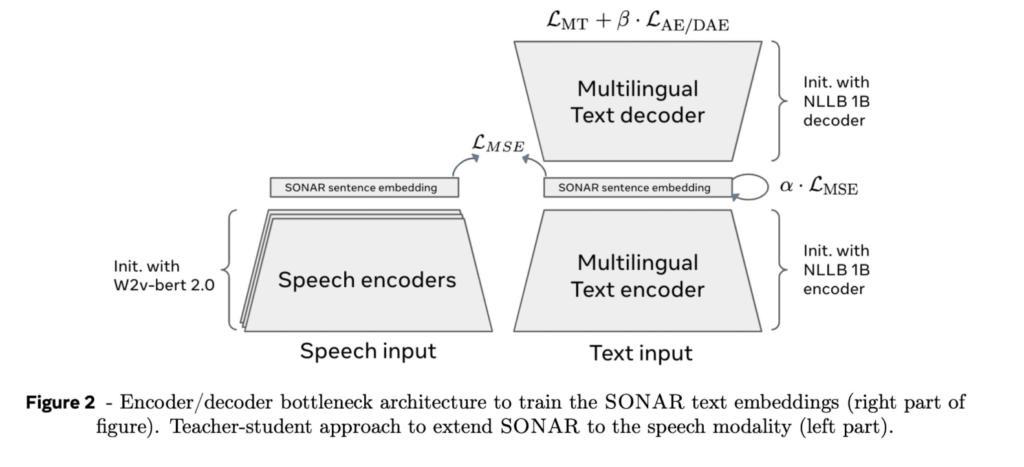
LCM透過SONAR嵌入空間對句子進行編碼,將文字或語音輸入轉換為高維語義嵌入,並在這些嵌入上進行推理和產生。這使得模型能夠直接在句子層級處理訊息,而不是逐字生成。
思考方式像人類,從「概念」出發,邏輯更清晰。
能處理多語言、多模態任務,直接支援文字、語音甚至手語。
適合長文本處理,速度快,生成內容更連貫。
具備強大的零樣本泛化能力,不用額外訓練也能完成新任務。
對照項 傳統模型 (GPT) LCM
生成單位 單字或詞元逐字生成 句子或段落層級生成
多語言支援 英語為主,部分支援 支援200種語言
產生連貫性 長文本邏輯容易混亂 邏輯更清晰,一致性強
上下文處理 長上下文效能下降 更好處理長上下文
擴展能力 需重新訓練或微調 可直接泛化到新任務
LCM 解決了什麼問題
傳統LLMs的局限性
缺乏多層次推理能力:傳統LLMs(如GPT、Claude)在文本生成時逐字預測,雖然效果流暢,但缺乏明確的層次化規劃能力。
語言中心化問題:多數LLMs以英語為中心,對低資源語言的支援較弱。
長文本產生一致性問題:在產生長文本時,傳統LLMs難以保持邏輯一致性。
LCM如何改進
明確推理:透過引入層次化結構,LCM能夠在概念層級規劃文本的整體結構和邏輯。
多語言和模態支援:LCM基於SONAR嵌入,支援200種語言,能夠無縫處理多種模態(如文字、語音)。
提高生成效率和一致性:LCM以句子為單位進行推理,顯著降低序列長度,減少計算複雜度,同時提高生成的連貫性。
論文中探討了以下 三種主要模型架構,它們分別是針對不同任務需求設計的:
基礎模型 (Base-LCM):結構簡單,適合精確性要求高但邏輯不複雜的任務。
擴散模型 (Diffusion LCM):綜合表現最佳,適合複雜邏輯和長文本生成。
量化模型 (Quantized LCM):效率優先,適合多樣性生成和低運算資源情境。
1. 基礎模型 (Base-LCM)
核心特點:
基於標準的自回歸 Transformer 模型。
使用均方誤差 (MSE) 作為目標函數,直接預測下一句的語意嵌入。
優勢:
實作簡單,產生嵌入的精確度較高(L2 距離最低)。
劣勢:
缺乏多樣性:容易產生平均化的結果,不符合真實語意分佈。
上下文關聯性較弱,生成長文本時邏輯一致性較差。
2. 基於擴散的模型 (Diffusion LCM)
核心特點:
借鑒影像生成中的擴散模型(Diffusion Models)。
在擴散過程的嵌入空間中逐步產生下一句的語意嵌入。
模型變體:
單塔模型 (One-Tower):使用單一 Transformer 處理上下文和目標生成。
雙塔模型 (Two-Tower):上下文編碼與目標生成分離:
第一塔負責提取上下文語義資訊。
第二塔透過擴散過程產生下一句的嵌入。
優勢:
上下文關聯性強,生成結果連貫性和多樣性優。
特別適合長文本生成和複雜邏輯任務。
劣勢:
計算複雜度相對較高。
3. 量化模型 (Quantized LCM)
核心特點:
透過殘差向量量化 (Residual Vector Quantization, RVQ),將嵌入離散化。
使用離散單元進行推理和生成,輸出可以是離散或連續的目標。
模型變體:
離散目標 (Quantized-LCM-d):透過分類預測下一個量化單元。
連續目標 (Quantized-LCM-c):透過迴歸預測連續的目標嵌入。
優勢:
更有效率的運算和存儲,適合資源有限的場景。
支援控制生成多樣性(如透過溫度或採樣策略)。
劣勢:
在生成的語意精確性和連貫性上略遜於擴散模型。
LCM 的主要功能特點
特性:LCM 關注的是“概念”,即完整的句子或想法,而不是逐字處理。
優點:像人類一樣,從整體思考問題,再逐步填滿細節。
例如,寫文章時,LCM 先確定大綱,再產生具體內容,讓文章更有邏輯性。
以下是其主要功能特點:
1. 語言和模態無關性
核心能力:LCM可以在多種語言和模態之間處理訊息,而不依賴特定的語言符號或格式。
支援範圍:
200種語言的文字輸入。
76種語言的語音輸入。
可以跨語言生成,例如將中文語音轉化為英文文字。
典型場景:
多語言翻譯:能夠無縫處理低資源語言。
多模態任務:未來可能支援影片或手語生成。
2. 顯式的層次化推理
層次化結構:LCM像人一樣,從高層次的「概念」(句子層次)進行推理,再逐步精進到具體的生成內容。
解決的問題:
傳統模型在長文本生成中,前後邏輯容易出現不一致。
LCM可以先規劃文本的大綱(如章節、段落),再產生具體內容。
優勢:
提高了長文本生成的連貫性和一致性。
更容易進行局部編輯,例如修改一段內容時,不會破壞整體邏輯。
3. 強大的零樣本泛化能力
功能描述:無需每種語言或任務進行額外微調,LCM在預訓練後能直接應用到新的語言或任務。
效果:
跨語言生成:例如用德語的輸入直接產生法語的輸出。
跨任務遷移:如從摘要生成任務遷移到長篇文章擴展任務。
優勢:
減少對大規模訓練資料的依賴。
適配性更強,適合複雜、多樣化場景。
4. 高效處理長文本
技術優化:LCM以句子為單位進行推理,而非傳統模型的逐詞生成,顯著降低了計算複雜度。
表現:
更能理解長上下文,提高對大段文字的生成品質。
支援長文章生成,例如小說或學術論文的整體規劃。
應用場景:
產生連續性要求高的內容,如新聞稿、故事或技術文件。
5. 模組化和可擴充性
模組化設計:
概念編碼器(Concept Encoder):將句子轉換為高維語意嵌入。
概念推理器(Concept Reasoner):在嵌入空間中推理生成。
概念解碼器(Concept Decoder):將嵌入還原為自然語言。
靈活擴展:
可以單獨優化某個模組,例如新增對手語或視訊模態的支援。
易於添加新的語言或模態,不會影響現有系統。
6. 高階生成特性
多樣性生成:
支援同時產生多個合理的內容版本(擴散模型支援)。
例如同一個輸入,可以產生不同風格或語言的輸出。
生成控制:
提供使用者互動能力,可以局部調整生成結果。
例如修改生成段落的語氣、風格或語言。
7. 提供開源工具與程式碼
LCM的訓練程式碼和SONAR嵌入庫是開源的,支援研究人員和開發者在其基礎上進一步開發和優化。
開源工具支援多語言和多模態任務,降低了使用門檻。
LCM 的工作原理
LCM(大型概念模型)的核心工作原理是透過「概念」(例如句子層級的抽象語義)進行推理和生成,而不是傳統語言模型逐詞生成的方式。這種方式更接近人類的思考方式,從高層抽像到細節逐漸展開。
LCM 的架構包括以下主要模組:
概念編碼器 (Concept Encoder)
將輸入的句子或語音轉換為語義嵌入。
使用 SONAR 嵌入空間,這是一種語言和模態無關的高維語義表示。
概念推理器 (Concept Reasoner)
在嵌入空間中進行推理和產生。
實作從上下文產生下一句嵌入的功能。
概念解碼器 (Concept Decoder)
將產生的嵌入還原為自然語言(文字或語音)。
以下是 LCM 的具體工作原理分解:
1. 基礎架構:概念嵌入的核心
概念的定義:
LCM 中的「概念」是語言和模態無關的語意單元,例如一個句子或一個完整的想法。
每個概念在一個高維嵌入空間中表示,這個空間被稱為 SONAR 嵌入空間。
SONAR 嵌入空間:
SONAR嵌入空間是一個多語言、多模態的語意嵌入系統它能將一句話(無論是文字或語音)轉換為一個高維度的數學表示(即一個「向量」)。
這個「向量」是對句子意義的抽象表示,可以用來分析或產生新的內容。
高維度語意嵌入:指這些表示包含了句子的主要訊息,例如它的意思、語氣、上下文關係等,而不是具體的單字。
支援 200 多種語言(文字)和 76 種語言的語音,還可以擴展到其他模態(如手語)。
把語言或語音資料編碼成一個統一的、高度語意化的向量表示。
如何工作?
輸入:你給模型一個句子(例如「今天的天氣真好」)或一句話的語音。
編碼:SONAR系統會把這句話轉換成向量(例如一個由數字組成的列表:[1.2, -0.3, 0.5, …])。
這個向量不僅代表句子的意思,還能跨語言或模態使用。例如,這個向量可以同樣適用於英文、法文、中文的表達。
模型如何處理資訊?
傳統模型的做法:
逐字產生:從第一個單字“今天”開始,然後預測下一個單字“的”,再預測“天氣”,依序產生。這種方式效率較低,產生長文字時容易出錯。
LCM的做法:
LCM直接把整句話看成一個整體「概念」來處理,而不是逐字去產生。
例如,如果想要產生“今天的天氣真好”,模型會預測整句話的語義向量(而不是逐個單字),然後直接還原為具體語言。
為什麼這種方式更有效率?
句子層級處理:
透過直接處理「句子」這種更高層次的單位,LCM可以避免逐字推測的低效率和錯誤。
例如,在寫故事時,它可以先決定“這一段的主題是愛”,然後產生具體內容。
跨語言能力:
由於SONAR嵌入是語言無關的,LCM可以輕鬆地處理多語言任務。例如,中文的輸入句可以直接用SONAR表示,然後轉換為英文輸出。
2. 工作流程
LCM 的工作流程分為以下階段:
(1)輸入處理
多模態支援:
輸入可以是文字、語音或其他模態的內容。
使用 SONAR 編碼器將輸入分割成句子,並將每個句子轉換為概念嵌入(語義向量)。
(2)概念推理與生成
概念序列處理:
LCM 使用類似 Transformer 的架構處理這些概念嵌入序列。
根據輸入的概念嵌入,模型產生下一步的概念嵌入。
推理過程:
模型會基於前面的語意上下文,預測下一個概念嵌入。
透過遞歸的方式,逐步產生完整的概念序列。
(3)輸出解碼
概念到語言:
使用 SONAR 解碼器將概念嵌入解碼為文字、語音等具體模態。
解碼器是語言無關的,可以根據需要產生不同語言或模態的輸出。
3. 多種建模方法
LCM 提供了三種主要的建模方式,每種方式適應不同任務和需求:
(1)基礎模型(Base-LCM)
原理: 基於傳統的迴歸方法(均方誤差,MSE)直接預測下一步的概念嵌入。
特點:
簡單直接。
適合單一預測任務,但在生成多樣性和複雜場景中表現稍遜。
(2)基於擴散的 LCM(Diffusion-LCM)
原理: 從雜訊中逐步移除無關訊息,產生語意向量嵌入。
擴散過程:
前向擴散: 對輸入嵌入逐步加入噪聲,產生一個噪聲序列。
反向去噪: 模型從雜訊中逐步還原真實的語意嵌入。
特點:
能夠產生多個可能的語意結果。
適合任務多樣性較強的場景。
(3)量化模